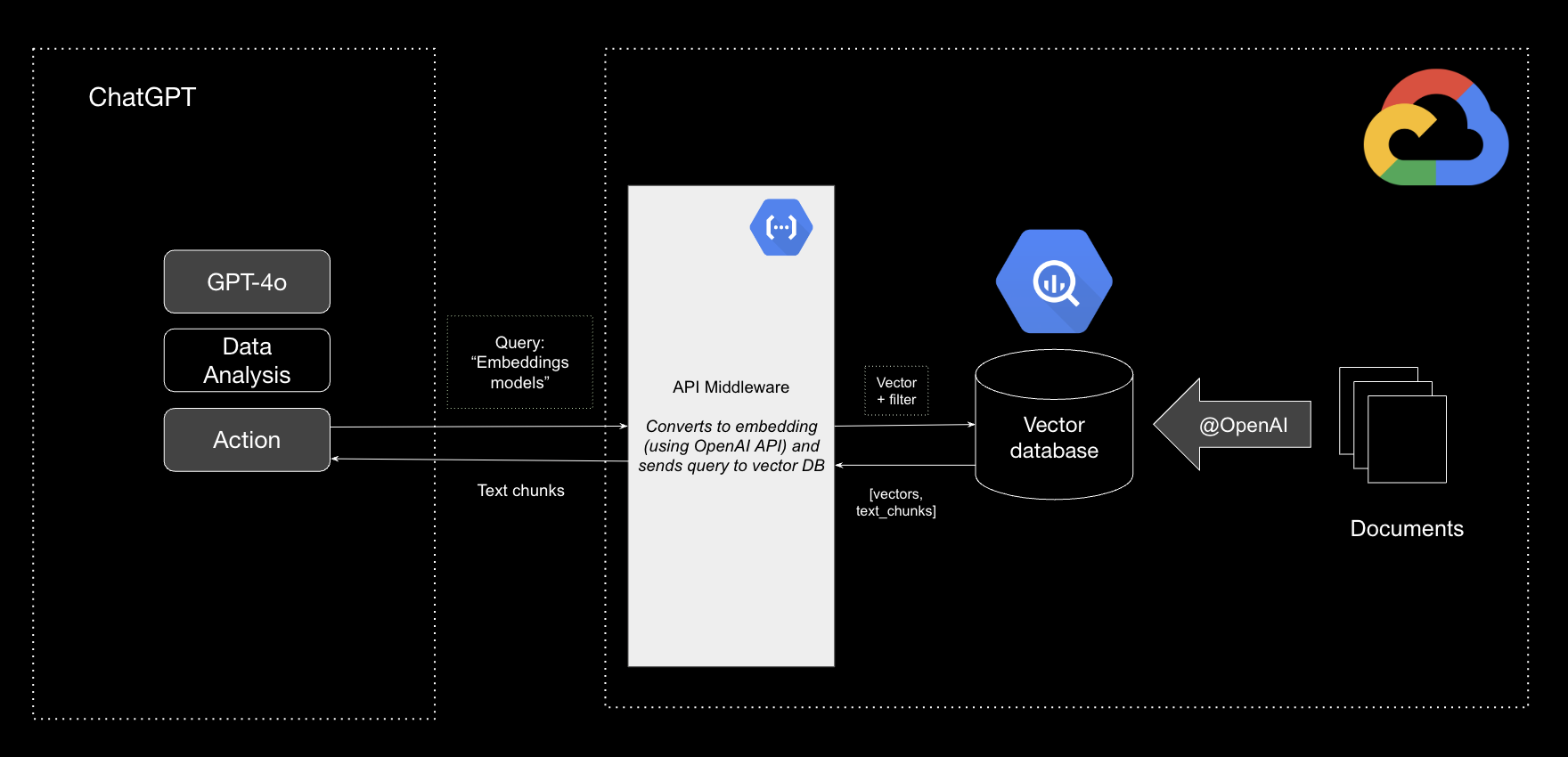
This notebook provides step-by-step instructions on using Google Cloud BigQuery as a database with vector search capabilities, with OpenAI embeddings, then creating a Google Cloud Function on top to plug into a Custom GPT in ChatGPT.
This can be a solution for customers looking to set up RAG infrastructure contained within Google Cloud Platform (GCP), and exposing it as an endpoint to integrate that with other platforms such as ChatGPT.
Google Cloud BigQuery is a fully-managed, serverless data warehouse that enables super-fast SQL queries using the processing power of Google's infrastructure. It allows developers to store and analyze massive datasets with ease.
Google Cloud Functions is a lightweight, event-based, asynchronous compute solution that allows you to create small, single-purpose functions that respond to cloud events without managing servers or runtime environments.
Prepare Data Prepare the data for uploading by embedding the documents, as well as capturing additional metadata. We will use a subset of OpenAI's docs as example data for this.
This section guides you through setting up authentication for OpenAI. Before going through this section, make sure you have your OpenAI API key.
openai_api_key = os.environ.get("OPENAI_API_KEY", "<your OpenAI API key if not set as an env var>") # Saving this as a variable to reference in function app in later stepopenai_client = OpenAI(api_key=openai_api_key)embeddings_model ="text-embedding-3-small"# We'll use this by default, but you can change to your text-embedding-3-large if desired
We're going to embed and store a few pages of the OpenAI docs in the oai_docs folder. We'll first embed each, add it to a CSV, and then use that CSV to upload to the index.
We are going to use some techniques highlighted in this cookbook. This is a quick way to embed text, without taking into account variables like sections, using our vision model to describe images/graphs/diagrams, overlapping text between chunks for longer documents, etc.
In order to handle longer text files beyond the context of 8191 tokens, we can either use the chunk embeddings separately, or combine them in some way, such as averaging (weighted by the size of each chunk).
We will take a function from Python's own cookbook that breaks up a sequence into chunks.
defbatched(iterable, n):"""Batch data into tuples of length n. The last batch may be shorter."""# batched('ABCDEFG', 3) --> ABC DEF Gif n <1:raiseValueError('n must be at least one') it =iter(iterable)while (batch :=tuple(islice(it, n))):yield batch
Now we define a function that encodes a string into tokens and then breaks it up into chunks. We'll use tiktoken, a fast open-source tokenizer by OpenAI.
To read more about counting tokens with Tiktoken, check out this cookbook.
defchunked_tokens(text, chunk_length, encoding_name='cl100k_base'):# Get the encoding object for the specified encoding name. OpenAI's tiktoken library, which is used in this notebook, currently supports two encodings: 'bpe' and 'cl100k_base'. The 'bpe' encoding is used for GPT-3 and earlier models, while 'cl100k_base' is used for newer models like GPT-4. encoding = tiktoken.get_encoding(encoding_name)# Encode the input text into tokens tokens = encoding.encode(text)# Create an iterator that yields chunks of tokens of the specified length chunks_iterator = batched(tokens, chunk_length)# Yield each chunk from the iteratoryield from chunks_iterator
Finally, we can write a function that safely handles embedding requests, even when the input text is longer than the maximum context length, by chunking the input tokens and embedding each chunk individually. The average flag can be set to True to return the weighted average of the chunk embeddings, or False to simply return the unmodified list of chunk embeddings.
Note: there are other techniques you can take here, including:
using GPT-4o to capture images/chart descriptions for embedding
chunking based on paragraphs or sections
adding more descriptive metadata about each article.
defgenerate_embeddings(text, model):# Generate embeddings for the provided text using the specified model embeddings_response = openai_client.embeddings.create(model=model, input=text)# Extract the embedding data from the response embedding = embeddings_response.data[0].embeddingreturn embeddingdeflen_safe_get_embedding(text, model=embeddings_model, max_tokens=EMBEDDING_CTX_LENGTH, encoding_name=EMBEDDING_ENCODING):# Initialize lists to store embeddings and corresponding text chunks chunk_embeddings = [] chunk_texts = []# Iterate over chunks of tokens from the input textfor chunk in chunked_tokens(text, chunk_length=max_tokens, encoding_name=encoding_name):# Generate embeddings for each chunk and append to the list chunk_embeddings.append(generate_embeddings(chunk, model=model))# Decode the chunk back to text and append to the list chunk_texts.append(tiktoken.get_encoding(encoding_name).decode(chunk))# Return the list of chunk embeddings and the corresponding text chunksreturn chunk_embeddings, chunk_texts
Next, we can define a helper function that will capture additional metadata about the documents. In this example, I'll choose from a list of categories to use later on in a metadata filter
categories = ['authentication','models','techniques','tools','setup','billing_limits','other']defcategorize_text(text, categories):# Create a prompt for categorization messages = [ {"role": "system", "content": f"""You are an expert in LLMs, and you will be given text that corresponds to an article in OpenAI's documentation. Categorize the document into one of these categories: {', '.join(categories)}. Only respond with the category name and nothing else."""}, {"role": "user", "content": text} ]try:# Call the OpenAI API to categorize the text response = openai_client.chat.completions.create(model="gpt-4o",messages=messages )# Extract the category from the response category = response.choices[0].message.contentreturn categoryexceptExceptionas e:print(f"Error categorizing text: {str(e)}")returnNone# Example usage
Now, we can define some helper functions to process the .txt files in the oai_docs folder. Feel free to use this on your own data, this supports both .txt and .pdf files.
defextract_text_from_pdf(pdf_path):# Initialize the PDF reader reader = PdfReader(pdf_path) text =""# Iterate through each page in the PDF and extract textfor page in reader.pages: text += page.extract_text()return textdefprocess_file(file_path, idx, categories, embeddings_model): file_name = os.path.basename(file_path)print(f"Processing file {idx +1}: {file_name}")# Read text content from .txt filesif file_name.endswith('.txt'):withopen(file_path, 'r', encoding='utf-8') asfile: text =file.read()# Extract text content from .pdf fileselif file_name.endswith('.pdf'): text = extract_text_from_pdf(file_path) title = file_name# Generate embeddings for the title title_vectors, title_text = len_safe_get_embedding(title, embeddings_model)print(f"Generated title embeddings for {file_name}")# Generate embeddings for the content content_vectors, content_text = len_safe_get_embedding(text, embeddings_model)print(f"Generated content embeddings for {file_name}") category = categorize_text(' '.join(content_text), categories)print(f"Categorized {file_name} as {category}")# Prepare the data to be appended data = []for i, content_vector inenumerate(content_vectors): data.append({"id": f"{idx}_{i}","vector_id": f"{idx}_{i}","title": title_text[0],"text": content_text[i],"title_vector": json.dumps(title_vectors[0]), # Assuming title is short and has only one chunk"content_vector": json.dumps(content_vector),"category": category })print(f"Appended data for chunk {i +1}/{len(content_vectors)} of {file_name}")return data
We'll now use this helper function to process our OpenAI documentation. Feel free to update this to use your own data by changing the folder in process_files below.
Note that this will process the documents in chosen folder concurrently, so this should take <30 seconds if using txt files, and slightly longer if using PDFs.
## Customize the location below if you are using different data besides the OpenAI documentation. Note that if you are using a different dataset, you will need to update the categories list as well.folder_name ="../../../data/oai_docs"files = [os.path.join(folder_name, f) for f in os.listdir(folder_name) if f.endswith('.txt') or f.endswith('.pdf')]data = []# Process each file concurrentlywith concurrent.futures.ThreadPoolExecutor() as executor: futures = {executor.submit(process_file, file_path, idx, categories, embeddings_model): idx for idx, file_path inenumerate(files)}for future in concurrent.futures.as_completed(futures):try: result = future.result() data.extend(result)exceptExceptionas e:print(f"Error processing file: {str(e)}")# Write the data to a CSV filecsv_file = os.path.join("..", "embedded_data.csv")withopen(csv_file, 'w', newline='', encoding='utf-8') as csvfile: fieldnames = ["id", "vector_id", "title", "text", "title_vector", "content_vector","category"] writer = csv.DictWriter(csvfile, fieldnames=fieldnames) writer.writeheader()for row in data: writer.writerow(row)print(f"Wrote row with id {row['id']} to CSV")# Convert the CSV file to a Dataframearticle_df = pd.read_csv("../embedded_data.csv")# Read vectors from strings back into a list using json.loadsarticle_df["title_vector"] = article_df.title_vector.apply(json.loads)article_df["content_vector"] = article_df.content_vector.apply(json.loads)article_df["vector_id"] = article_df["vector_id"].apply(str)article_df["category"] = article_df["category"].apply(str)article_df.head()
We now have an embedded_data.csv file with six columns that we can upload to our vector database!
We'll leverage Google SDK and create a dataset named "oai_docs" with a table name of "embedded_data", but feel free to change those variables (you can also change regions).
PS: We won't create a BigQuery index, that could improve the performance of the vector search, because such index requires more than 1k rows in our dataset which we don't have in our example, but feel free to leverage that for your own use-case.
# Create bigquery tablefrom google.cloud import bigqueryfrom google.api_core.exceptions import Conflict# Define the dataset ID (project_id.dataset_id)raw_dataset_id ='oai_docs'dataset_id = project_id +'.'+ raw_dataset_idclient = bigquery.Client(credentials=credentials, project=project_id)# Construct a full Dataset object to send to the APIdataset = bigquery.Dataset(dataset_id)# Specify the geographic location where the dataset should residedataset.location ="US"# Send the dataset to the API for creationtry: dataset = client.create_dataset(dataset, timeout=30)print(f"Created dataset {client.project}.{dataset.dataset_id}")except Conflict:print(f"dataset {dataset.dataset_id } already exists")
# Read the CSV file, properly handling multiline fieldscsv_file_path ="../embedded_data.csv"df = pd.read_csv(csv_file_path, engine='python', quotechar='"', quoting=1)# Display the first few rows of the dataframedf.head()
We'll create the table with the attribute name and types. Note the 'content_vector' attribute that allows to store a vector of float for a single row, which we'll use for our vector search.
This code will then loop on our CSVs previously created to insert the rows into Bigquery.
If you run this code multiple time, multiple identical rows will be inserted which will give less accurate results when doing search (you could put uniqueness on IDs or clean the DB each time).
# Read the CSV file, properly handling multiline fieldsdataset_id = project_id +'.'+ raw_dataset_idclient = bigquery.Client(credentials=credentials, project=project_id)csv_file_path ="../embedded_data.csv"df = pd.read_csv(csv_file_path, engine='python', quotechar='"', quoting=1)# Preprocess the data to ensure content_vector is correctly formatted# removing last and first character which are brackets [], comma splitting and converting to floatdefpreprocess_content_vector(row): row['content_vector'] = [float(x) for x in row['content_vector'][1:-1].split(',')]return row# Apply preprocessing to the dataframedf = df.apply(preprocess_content_vector, axis=1)# Define the schema of the final tablefinal_schema = [ bigquery.SchemaField("id", "STRING"), bigquery.SchemaField("vector_id", "STRING"), bigquery.SchemaField("title", "STRING"), bigquery.SchemaField("text", "STRING"), bigquery.SchemaField("title_vector", "STRING"), bigquery.SchemaField("content_vector", "FLOAT64", mode="REPEATED"), bigquery.SchemaField("category", "STRING"),]# Define the final table IDraw_table_id ='embedded_data'final_table_id =f'{dataset_id}.'+ raw_table_id# Create the final table objectfinal_table = bigquery.Table(final_table_id, schema=final_schema)# Send the table to the API for creationfinal_table = client.create_table(final_table, exists_ok=True) # API requestprint(f"Created final table {project_id}.{final_table.dataset_id}.{final_table.table_id}")# Convert DataFrame to list of dictionaries for BigQuery insertionrows_to_insert = df.to_dict(orient='records')# Upload data to the final tableerrors = client.insert_rows_json(f"{final_table.dataset_id}.{final_table.table_id}", rows_to_insert) # API requestif errors:print(f"Encountered errors while inserting rows: {errors}")else:print(f"Successfully loaded data into {dataset_id}:{final_table_id}")
Now that the data is uploaded, we'll test both pure vector similarity search and with metadata filtering locally below to make sure it is working as expected.
You can test both a pure vector search and metadata filtering.
The query below is pure vector search, where we don't filter out on category.
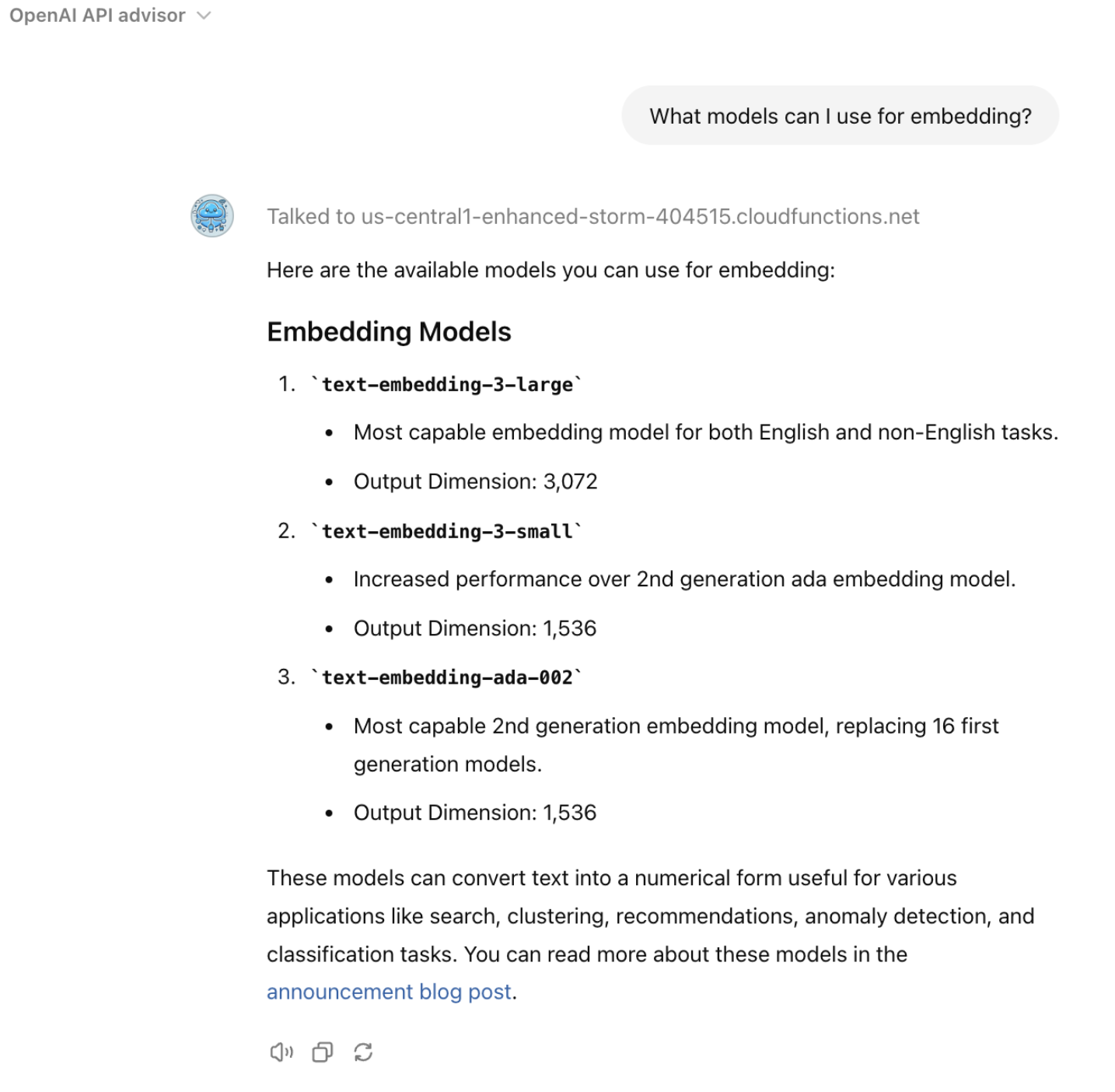
query ="What model should I use to embed?"category ="models"embedding_query = generate_embeddings(query, embeddings_model)embedding_query_list =', '.join(map(str, embedding_query))query =f"""WITH search_results AS ( SELECT query.id AS query_id, base.id AS base_id, distance FROM VECTOR_SEARCH( TABLE oai_docs.embedded_data, 'content_vector', (SELECT ARRAY[{embedding_query_list}] AS content_vector, 'query_vector' AS id), top_k => 2, distance_type => 'COSINE', options => '{{"use_brute_force": true}}'))SELECT sr.query_id, sr.base_id, sr.distance, ed.text, ed.titleFROM search_results srJOIN oai_docs.embedded_data ed ON sr.base_id = ed.idORDER BY sr.distance ASC"""query_job = client.query(query)results = query_job.result() # Wait for the job to completefor row in results:print(f"query_id: {row['query_id']}, base_id: {row['base_id']}, distance: {row['distance']}, text_truncated: {row['text'][0:100]}")
Metadata filtering allows to restrict findings that have certain attributes on top of having the closest semantic findings of vector search.
The provided code snippet demonstrates how to execute a query with metadata filtering:
query ="What model should I use to embed?"category ="models"embedding_query = generate_embeddings(query, embeddings_model)embedding_query_list =', '.join(map(str, embedding_query))query =f"""WITH search_results AS ( SELECT query.id AS query_id, base.id AS base_id, distance FROM VECTOR_SEARCH( (SELECT * FROM oai_docs.embedded_data WHERE category = '{category}'), 'content_vector', (SELECT ARRAY[{embedding_query_list}] AS content_vector, 'query_vector' AS id), top_k => 4, distance_type => 'COSINE', options => '{{"use_brute_force": true}}'))SELECT sr.query_id, sr.base_id, sr.distance, ed.text, ed.title, ed.categoryFROM search_results srJOIN oai_docs.embedded_data ed ON sr.base_id = ed.idORDER BY sr.distance ASC"""query_job = client.query(query)results = query_job.result() # Wait for the job to completefor row in results:print(f"category: {row['category']}, title: {row['title']}, base_id: {row['base_id']}, distance: {row['distance']}, text_truncated: {row['text'][0:100]}")
We'll deploy the function in main.py in this folder (also available here).
In a first step, we'll export the variables to target our table/dataset as well as to generate Embeddings using OpenAI's API.
# Create a dictionary to store the environment variables (they were used previously and are just retrieved)env_variables = {'OPENAI_API_KEY': openai_api_key,'EMBEDDINGS_MODEL': embeddings_model,'PROJECT_ID': project_id,'DATASET_ID': raw_dataset_id,'TABLE_ID': raw_table_id}# Write the environment variables to a YAML filewithopen('env.yml', 'w') as yaml_file: yaml.dump(env_variables, yaml_file, default_flow_style=False)print("env.yml file created successfully.")
We will now create a google function called "openai_docs_search" for our current project, for that we'll launch the CLI command below, leveraging the previously created environment variables. Note that this function can be called from everywhere without authentication, do not use that for production or add additional authentication mechanism.
Below is a sample OpenAPI spec. When we run the block below, a functional spec should be copied to the clipboard to paste in the GPT Action.
Note that this does not have any authentication by default, but you can set up GCP Functions with Auth by following GCP's docs here.
spec =f"""openapi: 3.1.0info: title: OpenAI API documentation search description: API to perform a semantic search over OpenAI APIs version: 1.0.0servers: - url: https://{region}-{project_id}.cloudfunctions.net description: Main (production) serverpaths: /openai_docs_search: post: operationId: openai_docs_search summary: Perform a search description: Returns search results for the given query parameters. requestBody: required: true content: application/json: schema: type: object properties: query: type: string description: The search query string top_k: type: integer description: Number of top results to return. Maximum is 3. category: type: string description: The category to filter on, on top of similarity search (used for metadata filtering). Possible values are {categories}. responses: '200': description: A JSON response with the search results content: application/json: schema: type: object properties: items: type: array items: type: object properties: text: type: string example: "Learn how to turn text into numbers, unlocking use cases like search..." title: type: string example: "embeddings.txt" distance: type: number format: float example: 0.484939891778730 category: type: string example: "models""""print(spec)pyperclip.copy(spec)print("OpenAPI spec copied to clipboard")
Feel free to modify instructions as you see fit. Check out our docs here for some tips on prompt engineering.
instructions =f'''You are an OpenAI docs assistant. You have an action in your knowledge base where you can make a POST request to search for information. The POST request should always include: {{ "query": "<user_query>", "k_": <integer>, "category": <string, but optional>}}. Your goal is to assist users by performing searches using this POST request and providing them with relevant information based on the query.You must only include knowledge you get from your action in your response.The category must be from the following list: {categories}, which you should determine based on the user's query. If you cannot determine, then do not include the category in the POST request.'''pyperclip.copy(instructions)print("GPT Instructions copied to clipboard")print(instructions)